"No more gray days!" We promised ourselves after yet another data incident. We had discovered that engagement metrics for Snapchat users on iPhones were being undercounted. The app wasn't sending all analytics events due to a bug. The anomaly was first spotted by our head of engineering when looking at our "daily metrics report". This report was also sent out to most of the company and the numbers in it had to be "grayed out" in the following days until we released an app update. It was an embarrassing and demoralizing failure. Every product-related decision thereafter would raise a question: Do we trust our data?
Unfortunately, most product teams grapple with this question daily. As a leader in the product and data engineering teams at Snap, I experienced variants of it first-hand at scale:
- Is the drop in engagement after a product release due to organic reasons or is it a measurement artifact?
- Did the recommendation feature start converting poorly because of poor ML models or do we have wrong data feeding into the real-time data pipeline for inference?
- Are the product changes driving positive impact across all customer segments? When we have a regression, do we have enough data to drill down across various user cohorts, geographies, devices, and software configurations to find the problem?
- Should we launch a feature with a limited set of conversion metrics for a key funnel?
- Can we confidently share key product metrics with our executive leadership, customers, partners, or investors?
Blocked on Data
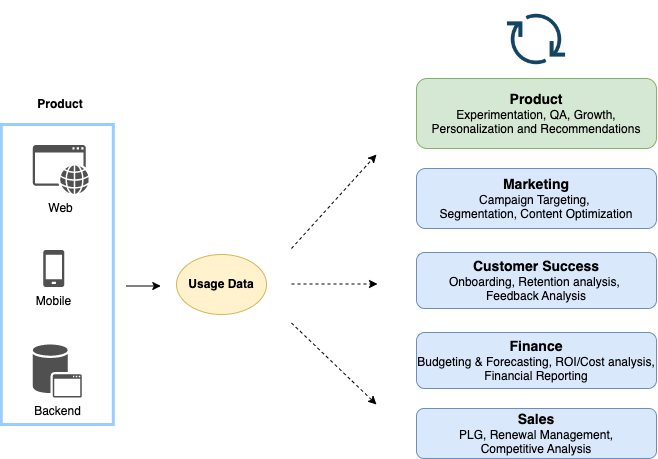
These problems are getting worse as product usage events increasingly drive use cases beyond dashboards:
- Product and growth teams perform rapid experimentation to make changes. These changes need to be measured accurately via A/B tests but they also end up breaking measurements.
- Products increasingly rely on ML-driven features such as feeds and recommendations. Usage events feed into ML features, often in real-time. Unlike in descriptive analytics, bad data can negatively impact user experience and revenue within seconds.
- Usage data enriched with other sources powers operational analytics for teams such as Sales, Marketing, Finance, and Customer Success. GTM motions such as Product-Led Growth (PLG) rely on such analytics being accurate.
Put simply, bad usage data now has a huge blast radius beyond broken dashboards. Often, it starts at the source and any downstream data observability or mitigations by data teams cannot fix it. The producers i.e. product teams cannot iterate fast because every "data incident" slows them and other functions down.
How can we ensure data is captured accurately at the source itself? How can we do so without overburdening and further slowing down the producers of data? The answer is to eliminate the toil of product instrumentation with better tools and not processes: today it requires a lot of effort to generate the right data.
You have a Data Deficit
When teams spin their wheels blocked on trustworthy data to do their jobs, they have what we will call a Data Deficit. They either do not have the complete data from their products to move forward or they don't trust the data that they do have.

They struggle with two key questions when acting on data:
- Is the data complete? Does it capture everything that we want to know?
- Is the data correct? Does it accurately reflect the reality of what we are trying to measure?
Completeness and correctness might seem related but are not the same things. For example, we have incomplete data if we want to know where in the checkout funnel customers are dropping off but we only capture the final click when they place the order. Even the "order placed" event could be incomplete e.g. it might not contain which page the order was placed from. The data would be incorrect if it doesn't accurately measure what happened e.g. if the "order placed" event is emitted only when orders are placed after the cart checkout flow but not from 1-click checkout.
Data Deficit starts at the Source
Achieving completeness and correctness is a concern at every stage of the data journey starting from creation to transformation to consumption but it becomes a critical issue during the first stage of data creation. Before we talk about data deficit at the source, some background on how data is created today.
Data originates in software applications - these are either the ones that you build and operate (first-party) or the ones you buy and use (third-party). It is what we call transactional data. An Order or a User in your ecommerce product or an Account object in Salesforce are examples of such data. Often this data is stored in an OLTP database like Postgres.
Data for the purpose of analytics or ML is usually generated explicitly and separately from transactional data, e.g. via clickstream/telemetry/domain events, but it can also be a copy of transactional data. In the latter case, it is a low-quality by-product - a form of digital exhaust. Events are the atoms of data. They represent change. Events eventually get transformed into source tables with facts and dimensions and then onto aggregated datasets, metrics, and ML models. We'll focus on first-party analytics events in this post[^1].
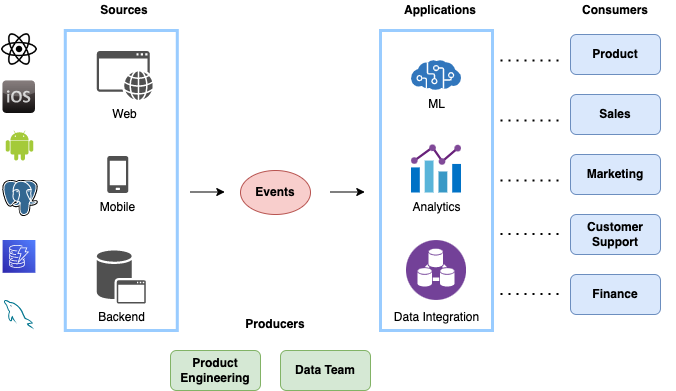
Source Data Deficit is Unforgiving
When data is found missing or incomplete after collection, it is relatively easy to fix the issue. We can simply re-run the pipelines because they derive data from the source data (events or transactional data). Similarly, if a dashboard is incorrect or stale on the consumption side, it can be regenerated. However, incomplete or inaccurate source data cannot be worked around. When a product change adversely affects how events are emitted, the fidelity of data is irreversibly compromised. It is a form of data loss that cannot be mitigated. When data deficit starts at the source, everything downstream becomes a slog:
- Product teams cannot innovate because they can't evaluate their experiments with deficient analytics events. They have to wait for a new product release to solve data issues. This can be a long process especially for mobile apps and could mean losing over a week waiting for the right data to become available[^2].
- Sales and marketing teams cannot confidently measure ROI on their activities to drive growth and revenue because they lack accurate conversion events.
- Finance teams can't make accurate cost and revenue projections or report trustworthy numbers to stakeholders, increasing business risk[^3].
- Data teams cannot reliably detect and mitigate upstream quality issues in their pipelines. They have poor visibility when product changes affect the schema or semantics of events and databases. No wonder, data quality continues to be the problem and investment area for them.
- Machine learning engineers cannot build robust models to optimize product experience and revenue. Unsurprisingly, better data collection and cleansing ranks as the most impactful area for ML practitioners.
So, the root cause of data deficit ends up being the process by which data is created at the source. The act of data creation is deeply tied with product iteration. Every downstream consumer of data is affected by this fundamental constraint. Unfortunately, fast product cycles produce data deficits which in turn slow down product iteration cycles creating a vicious circle.
The Data Creation Tax
To understand why getting data out of products is so difficult, it is crucial to understand the constraints under which data gets created from products. In most organizations, product teams prioritize shipping and testing features. Implementing telemetry to measure the usage or performance of what is being shipped is usually part of the scope but is often left for later in the development cycle. There are various reasons for this:
- Developers have to build the product or feature first before they can instrument it.
- Product teams don't know which questions they want to answer in depth with data until after they have tested the product themselves or with beta testers.
- The value of telemetry is unclear at this stage compared to other priorities that are required for shipping. Data is not a user-facing feature so it is not considered an absolute blocker. In the worst case, one can rely on the exhaust so the thinking goes.
- Implementing analytics correctly and responsibly requires coordination between multiple teams - Product, Engineering, Data, Privacy and Legal - across various functions. There are multiple handoffs and it can be a slow process.
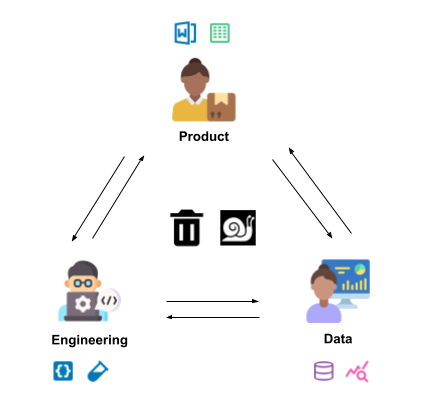
When the deadlines are tight, which they almost always are, analytics events are built quickly with very little thought put into data modeling and testing. Even when thought and care is put into the process, product teams will under-instrument their products because the value of asking for more instrumentation from developers is unclear at this stage. So, what is supposed to be a critical tool for measuring the success and effectiveness of the product and its impact on users and the business is handicapped right out of the gate. Once the feature is shipped, the emitted data gives less signal than they wished for and comes with more question marks than they expected. It is like putting a plane in the air with a barebones and barely functioning instrument panel.
Beyond initial implementation, maintaining and changing existing instrumentation is difficult as well. While developers have great tools to change, test, and maintain product changes, they don't have the same tooling for events. For example, when a developer makes a product change that affects where or how an event gets logged, they either don't know about this side effect or even if they do, it is hard to tell the magnitude of the impact on downstream consumers. Today's development and test tools don't come to their rescue. Events are critical to the success of the product and the business, yet they are the least reliable.
The Way Forward
Existing options in the market that attempt to improve data creation fall short in various ways.
- Tracking Plans are a project management tool used to define events and track their implementation. They don't help with verifying or validating the implementation and introduce additional friction. They have to be maintained in a spreadsheet and they diverge from the true source of truth which is the product code.
- Data Contracts are a recent proposal for explicit data APIs between transactional data producers and analytics customers. Although promising from a data quality POV, they don't focus on lessening the time spent in data creation. There aren't any publicly available implementations for contracts yet.
- Autocapture or Autotrack is a "no-code" approach that captures auto-generated analytics events from all user interactions. While it promises to reduce initial implementation time, it has proven to be fragile, noisy, and carries privacy risks, leading to its gradual abandonment by analytics providers.
At Syft, we are rethinking how product engineering teams can efficiently collect trustworthy events to deepen insights into their users and products. We strongly believe that product teams can iterate fast and generate high-quality events with the right tools at their disposal. We successfully addressed this challenge on a large scale at Snap. We have seen industry peers such as Facebook achieve the same. We believe that all engineering teams should have access to high-quality systems that these innovative and fast-paced companies have at their disposal. If the problems described in this post resonate with you and you would like to learn more about what we are building, we would love to hear from you at hello@syftdata.com.
[^1]: Third-party data is someone else's first-party data anyway.
[^2]: And this is for relatively fast moving companies Snap that have weekly release cycles
[^3]: Incorrect reporting of material metrics like DAU, accidental PII capture in events, etc trigger regulatory/shareholder/customer lawsuits that cost billions of dollars.